|
|
All the work done in the virtual environment proved the validity of the proposed approach. Reconstructing posture using silhouettes only is a valid tool to perform non intrusive motion capture. Also the measurements done are satisfactory, with a precision apparently sufficient for many practical applications.
In a real environment, the three stages of the proposed process will remain unchanged: from each camera a silhouette is extracted, the volume of the moving subject is reconstructed at the desired resolution and posture reconstruction is then obtained by fitting a 3D model to the reconstructed volume.
However, working in a real environment introduces several practical problem not present in the virtual environment.
The cameras should be accurately calibrated to establish relationship between the 3D world of the active area and the 2D space of the image plane. This could be done using Tsai’s method, but it requires an accurate identification of 3D reference points to obtain all the camera parameters. Reference points are obtained by means of a particular calibration object, that is an indeformable structure containing a grid of square of known position and dimension. The squares have different colors and are arranged on patterns that allows the calibration process to clearly identify the face of the object it belongs to, and thus to obtain the complete 3D coordinates of the reference points.
The silhouette extraction in the virtual environment was performed by means of a simple chroma key classification since the background had uniform color. This is not likely to happen with real images and in general the background might be a complex scene containing different objects of different color. Lighting conditions might change as well during the sequence due to light reflections on moving objects or to cast shadows. Besides, digitized images might contain noise that must be filtered.
Finally, as we stated in the introduction, the advantage of using model-based reconstruction is the possibility to exploit the whole model surface to evaluate a similarity parameter between the model pose and the image data. Therefore the accuracy of the posture reconstruction process is enhanced improving the resemblance between the moving object and the model used to fit the volume. For this reason the cylinder model is inadequate to achieve the required precision and a more anthropomorphous model should be used instead.
The chosen camera model allow us to use common camera and is able to cope with lens radial distortion. Before the capture session begins, the system and the working area should be accurately calibrated, to ensure correct correspondence between the viewing cone of each camera and the 3D common world. The calibration is performed with a particular object that has been carefully constructed and measured whose purpose is to recover the camera parameters by means of a set of correspondences between 3D points and image plane 2D points, such that back-projection of 3D world on camera images can be worked out precisely by the system.
The technique used for three dimensional calibration of the camera refers to the work of Tsai. The camera model is based on the so-called pin-hole model. The pinhole model is an ideal camera model in which the rays from 3D world points to 2D image points pass through one point. The pinhole model does not include any types of distortion, so the model should be modified to consider at least radial lens distortion.
Tsai’s algorithm requires for each camera a set of 3D world coordinates of feature points and the corresponding 2D coordinates of the feature points in the image. The feature points are acquired by means of a particular calibration object.
The calibration object is an indeformable structure containing a grid of squares of known position and dimension. The object is a cube and the reference points are contained on its faces. The squares have different colors and are arranged on patterns: each patterns is characterized by a peculiar combination of color that clearly identifies the face of the cube it belongs to (see Fig. 1).

Fig. 1: calibration object
The points selected as references are the barycenter of the blobs (Fig. 2). Simple geometrical considerations can be applied to work out the correspondence between the pattern analyzed and the cube, establishing correct matching between 3D world points and 2D points in the image plane.
The reference system of the active space will be centered on the calibration cube. Since Tsai’s algorithm requires a set of non coplanar reference points to reduce the calibration error, it is sufficient that on each image at least two of the faces of the calibration cube are visible.

Fig. 2: identification of the reference points
Silhouette extraction
Our approach to silhouette extraction is mainly based on the ideas presented in Wren (1997) and Yamada et al. (1998). Since we use only stationary cameras, the silhouette extracting system will be processing a scene that consists of a relatively static situation, such as an animation studio or an inner location, and only one single moving person. Thus we can try to define a model of the background scene and compare it with the current frame. Defining a likelihood parameter, we can compare each pixel of the image with the corresponding pixel on the scene model to decide if the pixel belongs to the silhouette or not. Cast shadows are identified and removed using the luminance information of the pixels.
After this identification process it is necessary to apply a post processing phase. Unavoidably the silhouette will contain some spurious pixels, "interlacing" effects from video digitalization or other anomalies. So resulting image is filtered for size in order to remove spurious features or to fill undesired holes in the silhouette.
In Fig. 3a is depicted the scene model built for one of the cameras used into the test sequence, while in Fig. 3b is shown one of the frames of the sequence, in which a person is moving into the active area. In Fig. 3c-d is shown the result of the silhouette extraction process: the red pixels represent the silhouette and the gray pixels the cast shadows and the spurious pixels that are removed from the silhouettes.




Fig. 3 (a-d): the scene model, a frame of the sequence and the extracted silhouette
The process of posture reconstruction strongly relies on the similarity between the moving object and the model used to fit the volume. The cylinder model is too simple to provide the accuracy required to capture the motion of a real human performer and a more anthropomorphous model should be used instead.
Our human body model has fifteen segments which are connected by rotational joints. The model is composed by the following body parts: head, trunk, pelvis, upper arms, forearms, hands, tights, shanks and feet.
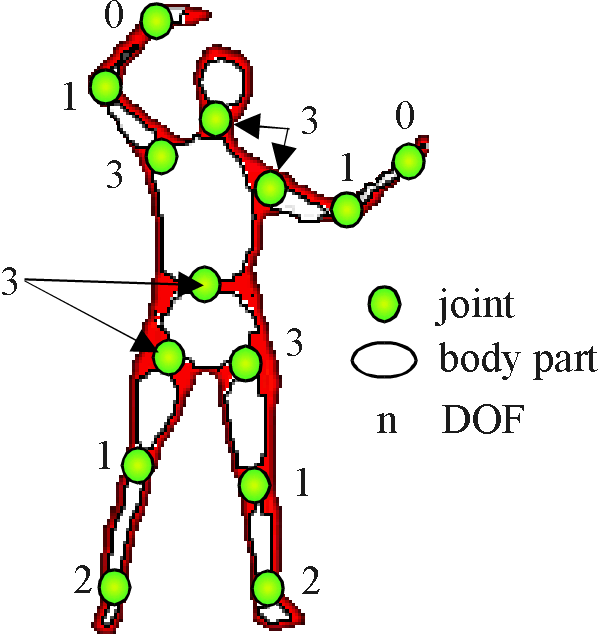
Fig. 4: DOF of the model
As for the cylinder model, segments are organized in a tree whose root is located in the pelvis (see Fig. 4). Each node rules the transformation of its leaves. A local Cartesian coordinate system is associated to each segment; this coordinate system is located in the center of rotation of the segment and aligned with its rotational axes.
The surface is defined through a triangular mesh composed of 584 vertices and 852 triangles and is depicted in Fig. 5. The complete set of shape parameters varies according to the performer characteristics.

Fig. 5: the human body model
Having a surface defined by a polygonal mesh allows to model more accurately the shape of the real human body with respect to using a geometric surface, but introduces several disadvantages. The main drawback is that pose reconstruction process requires to maximize a similarity function based on the distance function between the voxels of the VI and the surface of the model: evaluating the distance between a point and a triangular mesh involves finding the closest triangle to the point, a solution that severely increases the computational burden of function evaluation.
In order to reduce the number of computations required, each segment is approximated by an oriented bounding ellipsoid, that is an ellipsoid oriented along the local frame whose dimensions are given by the bounding box of the segment computed when the local coordinate system of the segment is oriented along the global coordinate system (see Fig. 6).
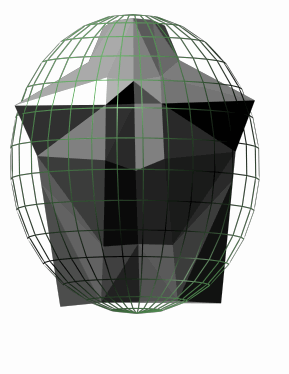
Fig. 6: oriented bounding ellipsoid (OBE)
The posture reconstruction process has been divided into two phases. In the first phase, the oriented bounding ellipsoid (OBE) is used as an approximation of the segment and the similarity function between the reconstructed volume and the model is evaluated by summing the squared distances between each voxel center and its closest OBE. This approximated similarity function is optimized at a coarser level; then a finer optimization is performed by considering as similarity function the D(Ã,R) function previously introduced.
In this section we present and discuss the precision performances of our algorithm relative to the computation of the posture of a real performer. Before attempting the reconstruction of real image sequences, we tested the new model into the virtual environment to evaluate the efficiency of the modified system.
Testing the new model in the virtual environment
We have developed several image sequences by means of simple motion algorithms to animate the dummy. Those algorithms are mainly based on the ones used to animate the cylinder model and are such to ensure the availability of a heterogeneous set of poses and orientations of the dummy. The sequences analyzed are the following:
As with the cylinder model, we have used three different voxel sizes (45, 35, and 25 mm) for volume reconstruction to evaluate how resolution affects posture precision. The maximal voxel size has been decreased since the new model has thin body parts which might easily intersect a voxel without intersecting any of its vertices.
The number of camera used is 5 for all the tests. To simulate the real environment we have planned to use, the dummy has a 4x4 meters active area and the camera are located at about seven meters away from the center of the active area. The model used to create the motion sequences is 1.80 m high. The results obtained are summarized from Table 1 to Table 4, where we report the posture errors averaged over all the frames of the sequences.
The average error obtained for the different sequences is between 16 and 21 mm, that is again almost 1% of the body size. The best reconstruction has been achieved for all the sequences using voxels of 35 mm. As can be seen, anyway, the accuracy of the reconstruction is relatively unaffected by the voxel size.

Fig. 7: the linear walk sequence
Fig. 8: the circular walk sequence

Fig. 9: the run sequence
Fig. 10: the Gym sequence
|
Voxel Dim. |
Mean Err. |
Max Err. |
Min. Err. |
St. Dev. |
|
25 |
17.05 |
21.54 |
12.61 |
2.37 |
|
35 |
16.31 |
23.25 |
9.91 |
3.23 |
|
45 |
18.69 |
23.93 |
11.60 |
3.36 |
Table 1: summary results for linear walk sequence
|
Voxel Dim. |
Mean Err. |
Max Err. |
Min. Err. |
St. Dev. |
|
25 |
22.54 |
34.18 |
13.51 |
3.99 |
|
35 |
21.67 |
29.68 |
12.07 |
3.91 |
|
45 |
22.90 |
33.55 |
12.64 |
3.69 |
Table 2: summary results for circular walk sequence
|
Voxel Dim. |
Mean Err. |
Max Err. |
Min. Err. |
St. Dev. |
|
25 |
24.34 |
37.22 |
16.37 |
5.03 |
|
35 |
18.44 |
25.57 |
9.20 |
3.79 |
|
45 |
22.10 |
31.61 |
12.32 |
4.55 |
Table 3: summary results for run sequence
|
Voxel Dim. |
Mean Err. |
Max Err. |
Min. Err. |
St. Dev. |
|
25 |
18.57 |
29.42 |
12.22 |
1.28 |
|
35 |
17.93 |
32.65 |
11.65 |
3.97 |
|
45 |
18.57 |
30.90 |
9.52 |
4.42 |
Table 4: summary results for gymnastic sequence
Recovering model postures from real image sequences
The video sequences we have used in our tests have been shot with courtesy of MOTEK Motion Technology of Amsterdam (The Netherlands) which put at our disposal its animation studio, the capture hardware and the machines (an Onyx and an Octane from Silicon Graphics) to test our algorithms on high speed parallel machines.
We have used five video cameras to obtain five different views of the performer. The camera have been calibrated beforehand so that their positions and orientations in the world coordinate are known. The cameras have been synchronized by flashing a light at the outset and detecting the starting video frames containing the flash.
The actor performed freely since we wanted to test our approach on real unconstrained motion, and the videos contain sequences of walking, rotating, sitting and bending.
Due to practical constraints it was not possible to put a camera over the head of the performer and also the distribution of the camera in the active space was more related to the length of the available cables than to other factors. One disadvantage of this is that the reconstructed volumes are really bulgy in several frames. Despite this drawback, however, the reconstructed sequence looks satisfactory when seen at real frame rate (25 frame/s). Some frames of the sequence from the five views are shown in Fig. 11, while Fig. 13 shows the composition of real and virtual model (Fig. 12 contains the same frames with only the real performer).














Fig. 11: frame 1, 21 and 41 of the sequence (camera 1-5)








Fig. 12: outtakes from camera 2









Fig. 13: reconstructed postures